During this 5-day bootcamp on machine learning, attendees will be introduced to the mathematical underpinnings of each method, how and why each method is applied, and the limitations, assumptions, and sensitivities of each method, which when violated can result in break down and failure. Example applications for each method will be covered using empirical public domain data, with comparison of results for the methods and data considered.
Attendees will receive a licensed Enterprise version of the Explorer package (windows only), and the 388-page User's Guide. Computer labs will be performed after each topic (subtopic) is covered, so that implementation or interpretation questions can be answered during the example runs.

TEXT MINING AND N-GRAM ANALYSIS
- Word frequencies
- Stopwords
- Stemming
- N-grams
- Concept clusteres
- Sentiment mining
CLASS DISCOVERY
- Crisp K-means Cluster Analysis (CKM)
- Distance Metrics
- Cluster Validity
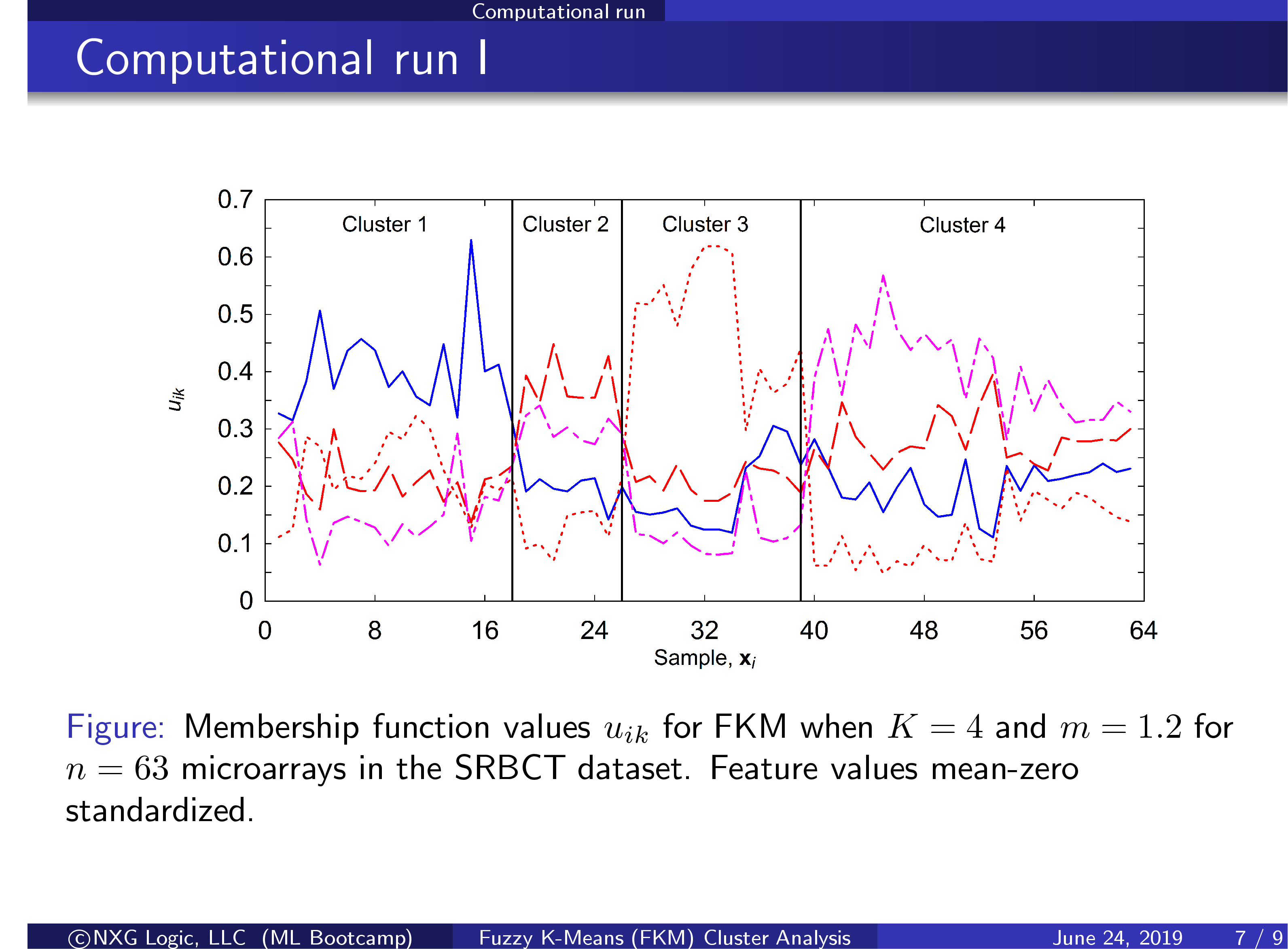
- Fuzzy K-means Cluster Analysis (FKM)
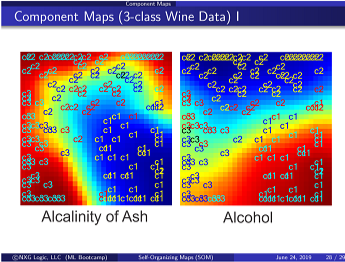
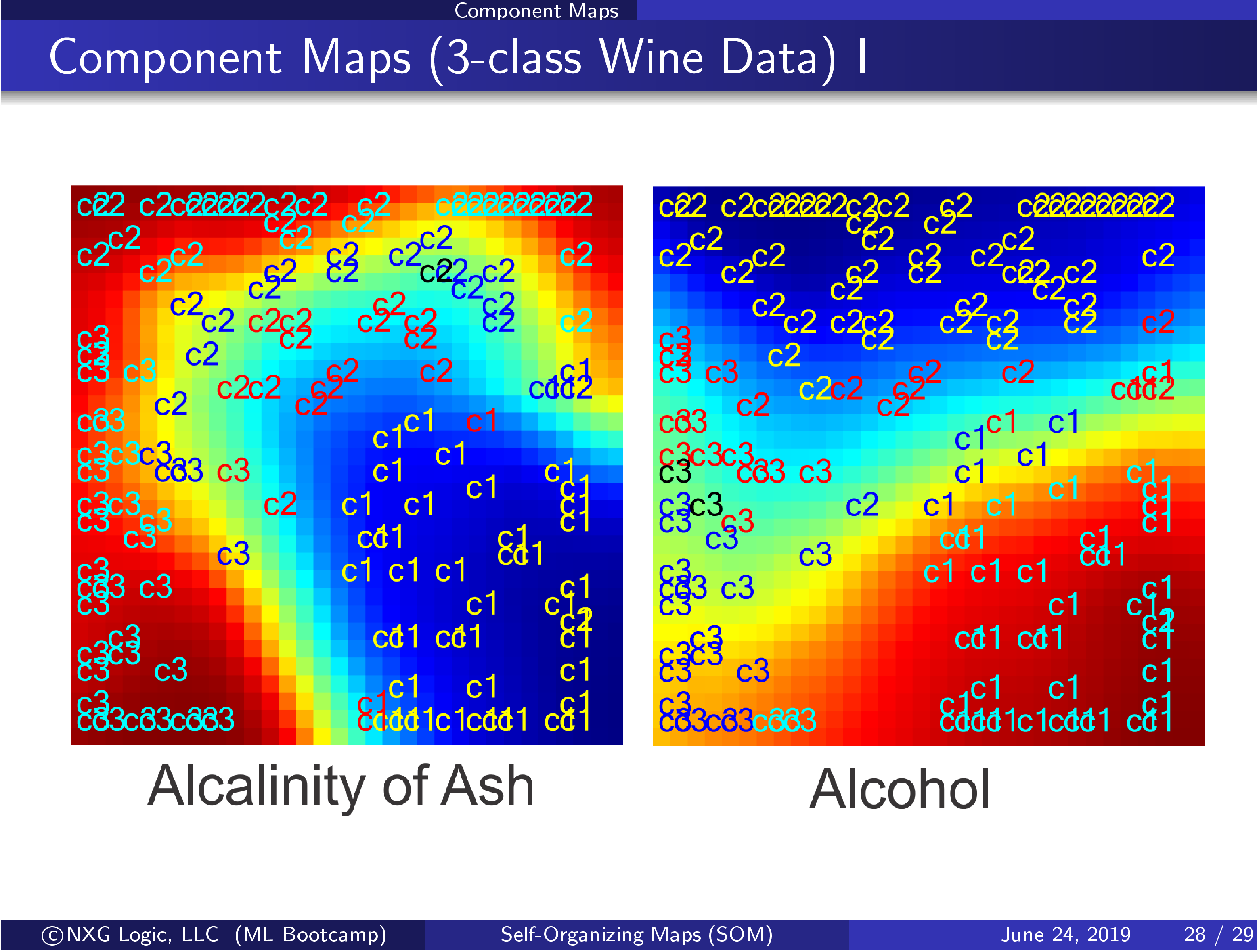
- Self-Organizing Map (SOM)
- Unsupervised Neural Gas (UNG)
- Gaussian Mixture Models (GMM)
- Unsupervised Random Forests (URF)
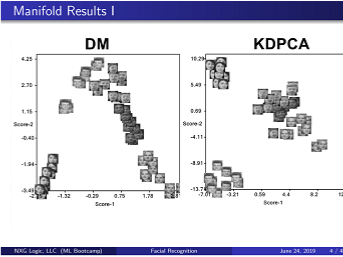
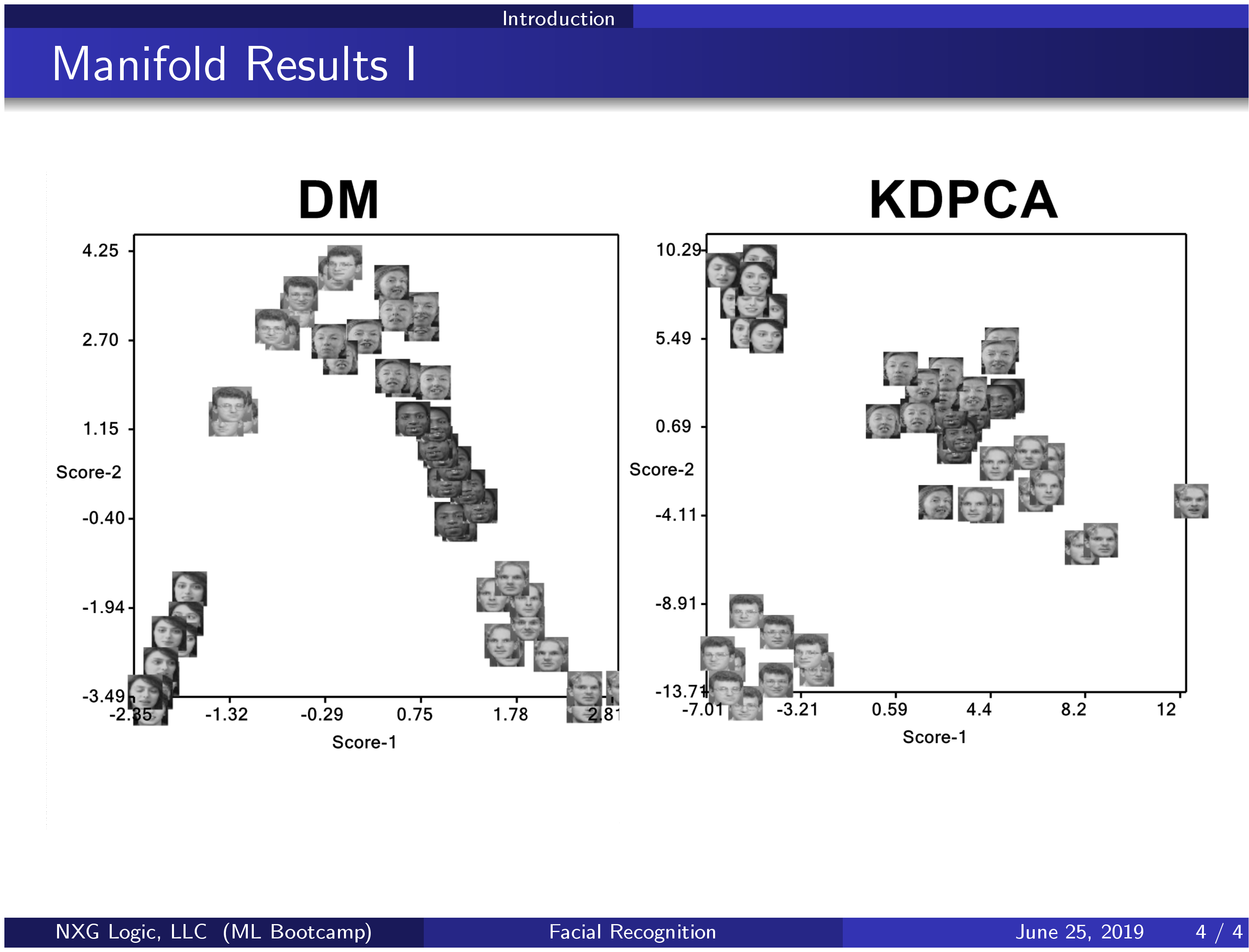
- Non-Linear Manifold Learning (NLML)
- Principal Components Analysis (PCA)
- Component Subtraction
- Covariance Matrix Shrinkage
- Kernel PCA (KPCA)
- Diffusion Maps (DM)
- Local Linear Embedding (LLE)
- Laplacian Eigenmaps (LEM)
- Locality Preserving Projections (LPP)
- Stochastic Neighbor Embedding (t-SNE)
- Sammon Mapping (Sammon)
- Classic Multidimensional Scaling (CMDS)
- Non-Metric Multidimensional Scaling (NMMDS)
- Hierarchical Cluster Analysis (HCA), dendograms, and heat maps
FEATURE SELECTION
- Introduction and Requirements
- Avoiding information leakage
- Cross-validation and Repartitioning
- Class Comparisons During CV
- Filtering Methods
- Generation of Non-Redundant Feature List
CLASS PREDICTION
- Linear Regression (LREG)
- Decision Tree Classification (DTC)
- k-Nearest Neigbor (kNN)
- Naïve Bayes Classifier (NBC)
- Linear Discriminant Analysis (LDA)
- Quadratic Discriminant Analysis (QDA)
- Learning Vector Quantization (LVQ1)
- Random Forests (SRF)
- Polytomous Logistic Regression (PLOG)
- Particle Swarm Optimization (PSO)
- Kernel Regression (RBF) and RBF Networks (RBFN)
- Support Vector Machines (SVM)
- Supervised Neural Gas (SNG)
- Mixture of Experts (MOE)
CLASSIFIER PERFORMANCE
Cross validation:
- Bootstrap
- K-fold
- Leave one out (LOOCV)
Class prediction performance:
- Sensitivity/specificity
- Committee voting and classifier fusion
- Boosting weak classifiers
- Classifier diversity: kappa vs. error
- Receiver operator characteristic (ROC) curves
- ROC area under the curve comparisons for all pairwise 2-class comparisons,
- Average AUC
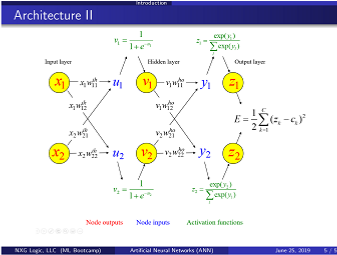
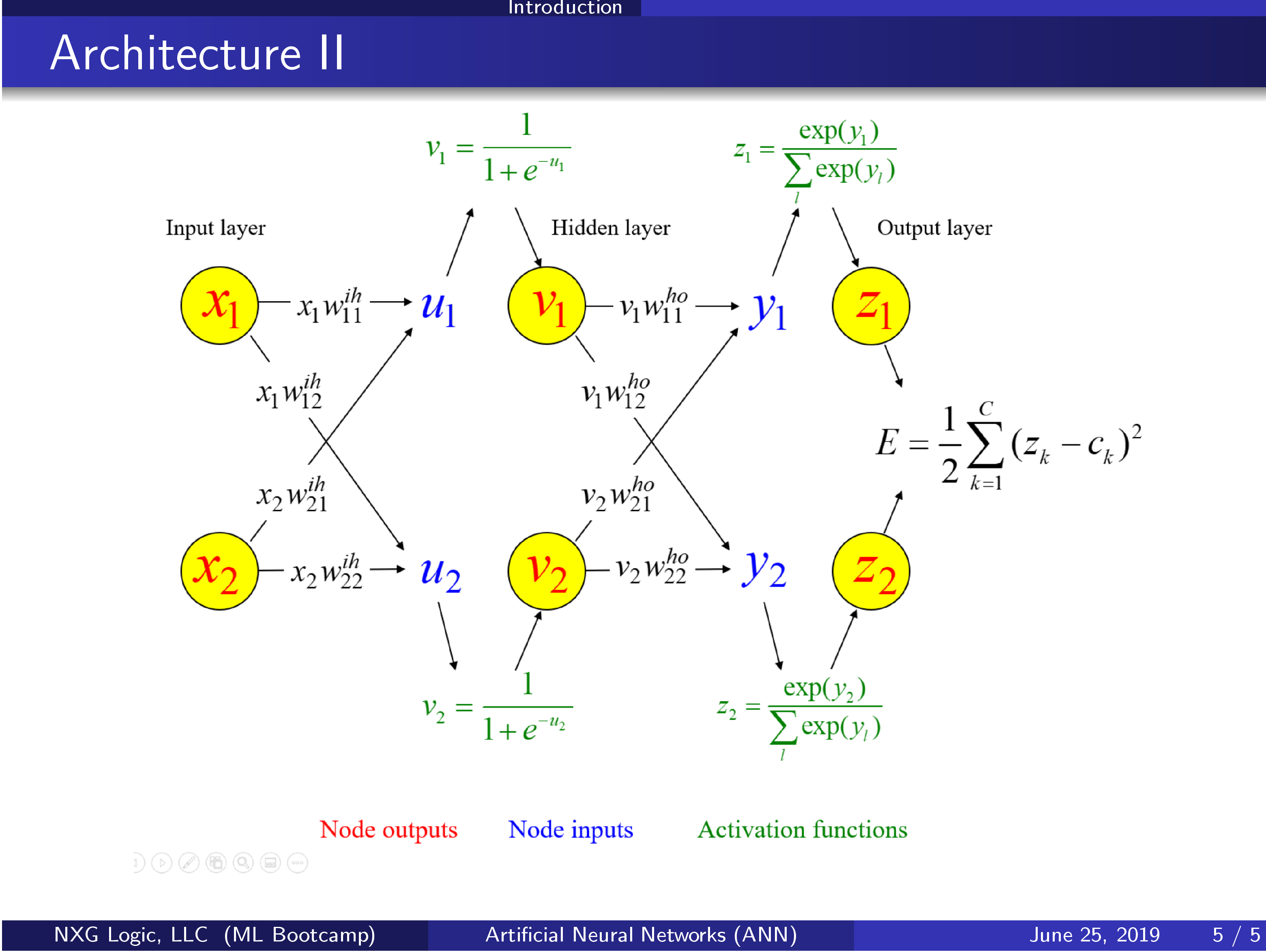
NEURAL NETWORKS
- Classification vs. function approximation
- Types
- Architecture
- Supervised vs. Unsupervised
- Autoencoding
- Regularization
- Dropout
- Momentum
- Learning rate
- Dimension reduction and decorrelation
- Input layer
- One hidden layer
- Multiple hidden layers
- Output layer
Activation functions and their derivatives:
- Identity
- Logistic
- Softmax
- tanh
- Hermite
- Laguerre
- Exponential
- RBFN
Back-propagation learning:
Connection weight updating:
Objective functions:
PARTIAL LEAST SQUARES
- Principal components regression
- Ridge regression
- Latent root regression
- Maximum covariance analysis
- Weight updating during iterations
- Regression coefficients
- Estimating outputs (yhats)