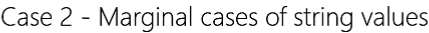Automatic de-stringing of input data
(Free Edition) Whenever you have input variables whose values erroneously contain string characters, such as "-", "?", or "NA", almost every statistical software package will assign the variables to be string variables. However, with Explorer, you can set the percentage of rows required to have string values in order to assign a variable as string. For example, if the string variable criterion is set to 0.9, then for each variable, 90% of the input records need to have string values in order for the variable to be called string. Therefore, if there are a lot of erroneous junk string values in cells of an input Excel file, but less than 90% of the records have string values in them for a particular variable, the variable will be assigned to be numeric, and the string values will be set to missing.
Our experience is that by default, researchers commonly have erroneous string values in cells of numeric variables. Therefore, we guard against the assignment of numeric variables to string variables just because there happens to be one string value found. You can always get back to the research team who constructed the data, and tell them to fix the string errors in their numeric fields -- but for now, you need to get on with the analysis -- and therefore it is appropriate on a temporary basis to set string values to missing in order to obtain preliminary results as quickly as possible. There is no misunderstanding that you will get back to the database admin to sort out difficulties with the data, you just need to focus on getting a result with what you have in hand on a preliminary basis.
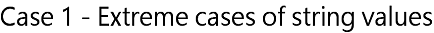
Consider the dataset below, with 2 grouping variables and 5 continuously scaled (numeric) variables, containing string values (colored in red) in certain cells. In fact, an entire line has "---" in every column.
Consider the dataset to the right, with 2 grouping variables and 5 continuously scaled (numeric) variables, containing string values (colored in red) in certain cells. In fact, an entire line has "---" in every column.
In other words, other software packages assume your numeric variables are truly string variables, like the following:
Most statistical packages will import all of the variables as string, since it only takes one string value in any cell to trigger a variable as being a string variable. None of these string variables can be employed in an analysis, until you (a) get back to the research group to confirm what the true values are, and (b) reset the true values or assign them to missing.
If there are many more variables and many more string values, you will need at least an hour to isolate all of them and then change them to missing.
Time required to fix these messy data: anywhere from 1 hour for a phone call, or several days via e-mail if you want to get back to the lab or database admin who provided the data for the ground truth answer on what the string values truly represent.
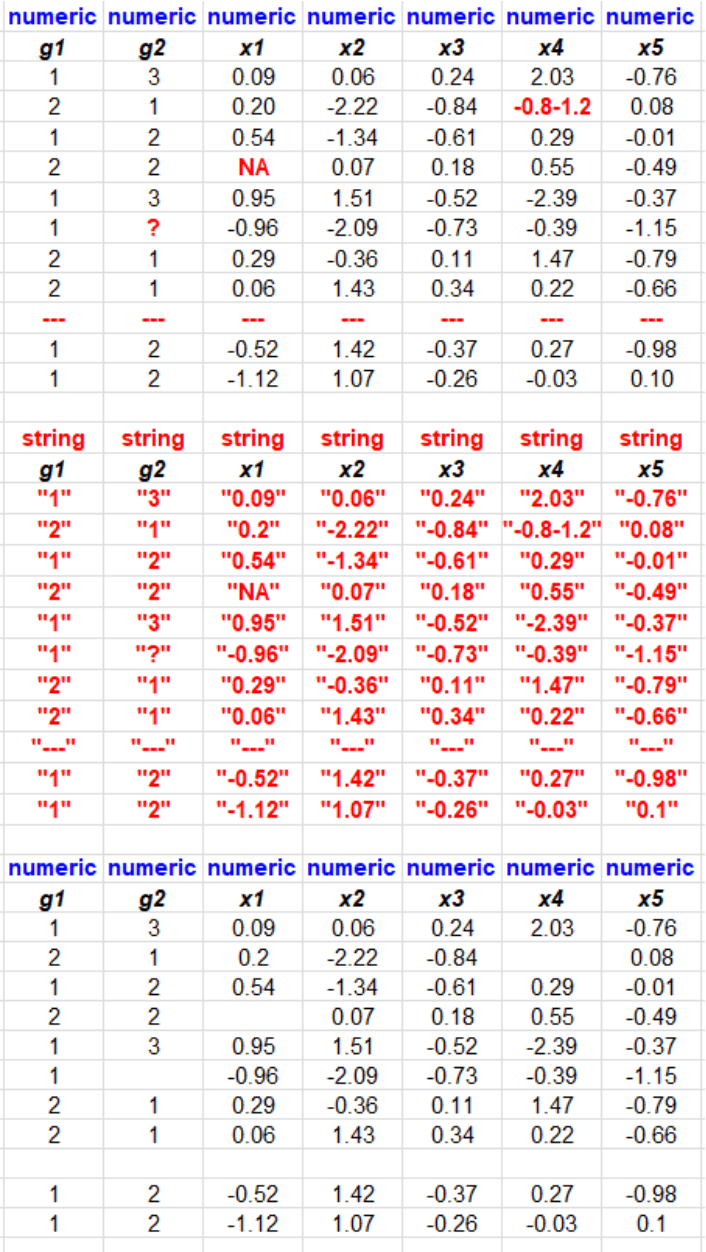
Using Explorer, however, the default import method will transform the string values into missing, because not more than 90% of the records contained string values. The 90% can be set in the default settings. Initially, there is nothing wrong with setting erroneous string values to missing, in a framework of conservatism.
In this case, assume that only several variables contain a single (or more) string value.
Time required to fix these messy data: anywhere from 1 hour for a phone call, or several days via e-mail if you want to get back to the lab or database admin who provided the data for the ground truth answer on what the string values truly represent.
Here, most software packages will import and assign the 3 variables with a single string value as string variables. Again, these variables cannot be used for analyses, until you get back to the data generating group to confirm what the true values represent.
Again, using Explorer, all input variables are immediately ready for analysis. You will still need to get back the the group who generated the data, but just not immediately if you want to perform an analysis. Again, initially, there is nothing wrong with setting erroneous string values to missing, in a framework of conservatism.